
2007年,得克萨斯州州长里克·佩里签署了一项决议,要求得克萨斯州所有12岁的女孩必须接种人乳头状瘤病毒疫苗(HPV),这种瘤会导致女性患宫颈癌。在2012年的共和党党内初选中,候选人之一的米歇尔·巴赫曼曾借这一事件攻击了里克·佩里,她声称一个女士告诉她:“我的女儿接种了那个疫苗,注射后她经受了智力发育迟缓的折磨”。
巴赫曼的逻辑有什么问题吗?或者说她是在引导我们推断——HPV疫苗引起了智力发育迟缓吗?让我们来分析一下。
我们需要想想巴克曼用以做证据的样本,这是美国所有注射了该疫苗的12岁女孩中的一例。这个有关智力发育迟缓的例子中只包含极少的样本(很低的样本量),要用它来证明注射过疫苗的女孩面临智力发育迟缓的风险是极其缺乏说服力的。
事实上,在女孩们注射疫苗之后,工作人员还对被随机选出的注射者和被注射者进行了好几次严格的随机对照实验。这些实验都包括了非常大的样本量。这些实验的结果并没有显示出,注射过疫苗的女孩比未注射过的女孩面临更高的智力发育迟缓的风险。
巴赫曼的样本里只包含一个注射过疫苗的12岁女孩——这是一种“恰好是他”似的统计。巴赫曼选来的样本顶多是偶然的,而非随机的。样本选择过程越接近随机选择的黄金标准——人群中的所有人被选中的概率是一样的,选择结果越可信。如果我们不知道一个样本是否是随机被选出的,那么我们对该样本进行的测量就会在某种未知的情形下发生偏差。
实际上,巴赫曼给出的样本甚至连一个偶然的样本都比不上。假设巴赫曼说的是实情,那么她本身便有很强的动机想把这个案例公之于众。而她可能没有说出实情,或者给她提供消息的人没说出真相,即提供消息的人说了假话。这个人可能十分确信自己告诉巴赫曼的事实。如果她的女儿注射了疫苗,而之后被诊断出了智力发育迟缓,那么这位母亲很有可能会犯事后归因的错误:A之后发生了B,所以A是产生B的原因。事实上,事件A先于事件B发生,并不一定代表事件A导致了事件B。不过对我而言,巴赫曼的这个例子还不是最糟糕的“恰好是他”的统计谬误。
我最喜欢的一个结合了“恰好是他”统计偏差的事后归因谬误例子是从一个朋友那里听来的,而他则是听到了两位老人的对话。第一个老人说:“我的医生告诉我,我必须戒烟,否则我会因此而死。”第二个老人说:“不!不要戒!我有两个朋友都听了医生的话戒了烟,然后他俩都在几个月之内就死了。”
样本和总体
回想第1章里提到的医院问题的推理。较小的医院里男孩出生比例超过60%的天数超过了较大的医院。唯有大数定律能解释这个问题:随着样本容量的增加,样本的值(例如均值或比例)就越接近总体对应的值。
在总体的规模达到极端的情况下,很容易就能看出大数定律的效果。假设某一天某家医院有10个婴儿出生。那么有多大概率这其中有60%或以上的婴儿是男婴呢?答案当然是,很有可能。我们当然不会怀疑,如果抛10次硬币,有可能6次正面朝上。假设某一天另一家医院有200个婴儿出生。有多大概率男女婴比例偏离正常值呢?答案很明显,几乎没有可能会偏离50%太远。这就像是抛了200次硬币,你期待有120次或更多的时候硬币正面朝上,而不是100次。
顺便提一句,我注意到样本统计值(均值、中位数、标准差等)的准确性与总体的规模是无关的。在美国,大多数对于大选的全国性调查仅包括1000个左右的被调查者,而调查者称调查结果与实际结果的偏差不超过±3%。一个1000人的样本就统计出了1亿总人口对某一位总统候选人的确切的支持率,结果几乎和1万人的样本一致。所以,当你支持的候选人的支持率领先对手8%的时候,别在意其他候选人的竞选代理人对民意调查结果的蔑视,他们宣称实际投票者有上百万,而参与民调的只有区区1000人。除非那些参与民调的人在总体中真的是十分不具有代表性(或者说极其小众),只有这样,那些你不支持的候选人才会最终胜利。而这就要引出我们的下一个话题,样本偏差。
只有当选取的样本没有偏差时,大数定律才是成立的。如果选取样本时允许出现一定概率的样本值错误的话,那么统计的结果可能会有偏差。如果你想调查一家工厂里有多少工人希望采取弹性工作制,而你的样本里只包含了男性工人或是在工厂的自助餐厅工作的工人,那么你得到的结果将会和以全厂所有工人为样本得到的结果有巨大差异,最终得到一个希望采取弹性工作制的工人比例的错误估算值。如果选取的样本本身就有偏差,那么这个样本规模越大,你就越有可能得到错误统计结果。
这里需要指出的是,实际上,全美民意调查并不是从总人口中随机取样的。如果是随机的,那么美国的所有投票者都应该有均等的机会成为被调查对象,但真实的调查并非如此,调查者是冒着会出现严重偏差的风险而进行取样的。美国历史上第一次对总统竞选进行的全国民意调查是由现今已不再发行的《文学文摘》杂志组织进行的。该调查结果显示,富兰克林·罗斯福将输掉1936年的总统大选,然而最终他以压倒性优势获胜。是《文学文摘》的问题吗?这次调查是通过电话进行的——而当时只有家境较好的人家(这样的富裕人家多半是属于或支持共和党的)才会安装电话。
而在2012年的美国大选中,相似的样本源偏差再次发生在一些民意调查中。拉斯姆森调查公司在电话调查中并没有通过拨打手机进行调查,他们因此忽略了一点:年轻人大多只使用手机,并且倾向于支持民主党。拉斯姆森公司因为系统性偏差,没有同时在固定电话和手机用户中抽样,最终高估了来自共和党的罗姆尼的支持率。
过去,只要人们接听调查电话或是开门接受上门调查员的访问,调查者就能得到一个近乎随机采集的样本。而今,民意调查的准确性在一定程度上依赖于调查者得到的数据和他们如何确定样本的直觉——衡量一个样本需要综合各类信息:被访者最终会参与投票的概率、其党派身份、性别、年龄、他们所属的社团成员、信仰的教派信徒在过去的投票情况,以及其他各种零碎古怪的信息。
找到真分数(true score)
请思考下面一些问题。
X大学设立了一个著名的音乐剧项目。该项目只为一小批具有非凡音乐潜质的高中毕业生提供奖学金。简是这个项目的负责人,她有一些朋友是当地高中的戏剧课老师。一天下午,她去斯普林菲尔德高中考察一个学生的情况,这个孩子是由其戏剧课老师强力推荐的,据说是一个十分优秀的年轻女演员。简观看了一出由罗杰斯与汉默斯坦创作的音乐剧的彩排,那个女孩子在剧中担任主角。结果,她说错了好几句台词,看上去她对角色的把握也不好,表现得像是几乎没什么舞台表演经验。简告诉她的同事,她现在十分怀疑她的朋友的判断。这是一个明智的结论吗?
乔是Y大学橄榄球队的球探,他去美国各地的中学练习赛上观看了比赛,考察那些由教练推荐给他的有潜质的年轻人。一天下午,他也来到了斯普林菲尔德高中考察一个有着出色得分纪录的四分卫。这个孩子有着出众的技术统计记录,并且得到了教练的高度评价。在练习中,这个四分卫传错了几次球,还投丢了几回,总共也没得到多少分。这位球探表示这个四分卫被高估了,并且建议Y大学不再考虑将他吸纳进来。这是一个明智的建议吗?
如果你认为简是明智的,而乔不是,那么只能说你比较了解体育竞赛的情况,却对戏剧演出知之甚少。如果你的结论正相反,则说明你熟悉戏剧演出而对体育竞赛不太了解。
我发现,那些不太了解体育的人往往认为乔可能是对的,即那个四分卫或许并没有那么有天赋;而了解体育竞赛的人更倾向于认为乔下的结论可能太过草率。他们认为,乔用于判断那个四分卫的表现的(极其小的)样本更可能是一种极端的情况,而给乔推荐那个孩子的教练的评价可能更接近实际情况。
那些不太了解戏剧表演的人可能会说那个女孩或许没有那么出色,然而了解戏剧的人会认为简对女孩的判断有些轻率。在其他条件都一样的情况下,你对某个特定领域了解得越多,你就更可能成功运用统计学概念来考虑相关问题。在这个例子中,重要的概念便是大数定律。
为什么这与大数定律有关呢?一个四分卫在一个或更多赛季的表现可以被看作评判其技术的可信依据。如果他的教练坚持认为他的确出色,那么我们有大量证据——众多技术统计数据——推断乔考察的这位球员真的特别优秀,乔自己的证据——一天中的一场比赛的表现与之相比就显得太不可信了。
一个球员自身表现的可变性,甚至是一支球队表现的可变性,就像一句老话形容的那样,在某一个星期日,美国全国橄榄球联盟中的任何一支球队都可以击败其他任何一支球队。这当然不是说所有球队的水平完全一样,这只是表明你需要一个相当大的样本量来准确评断不同球队的水平。
同样的推断逻辑也可以应用于那位戏剧项目负责人的判断。如果有好几位了解那位女演员的人都表示她有很高的才华,那么这位负责人就要对自己的判断三思。我发现很少有人意识到这一点,除了那些有一些戏剧表演经验或对表演领域十分熟悉的人。喜剧演员史蒂夫·马丁在自传中曾提到,几乎所有喜剧演员都有奉献出伟大演出的时刻。那些成功者不过是能时时保持良好水平以上的人。
用统计学术语来讲,球探和音乐剧项目负责人试图寻找的是他们考察的候选人的“真分数”。考察结果包括真分数和偏误。这个公式适用于几乎所有类型的测量项目,无论是人的身高,还是某一地的气温,都是如此。有两种途径可以提高分数的准确性。一种是应用更好的观测法——更好的码尺或是温度计。另一种是“消除”你在测量过程中可能出现的各种偏误,这可以用大数定律或是求取平均值来解决。大数定律这样发挥作用:你进行的测量越多,便会越接近于真分数。
访谈错觉
即使我们对一些领域有丰富的知识,也掌握了大量统计学原理,但仍有可能忘记大数定律的变化性和相关性。密歇根大学心理系对其顶尖的申请人进行面试,以做出最终的录取决定。我的同事对于和每个候选人进行20~30分钟的面试十分看重。“我认为她不合适。她似乎对我们讨论的课题没有太深的见地。”“他看上去十分合适。他谈到了他出色的荣誉论文,而且清晰地表达了他对如何做学术研究的理解。”
这里的问题是,我们究竟该依据什么来评判一个人,应该让他在一段很短时间内的表现成为主要依据吗?还是应该综合评估其各项条件:大学里的平均绩点,它总结了一个学生4年中在30门或更多课程中的表现;研究生入学考试(GRE)成绩,它从一个侧面反映了一个学生12年的学习成果和综合知识能力;推荐信,这通常会基于这个学生与推荐人长期的接触和交流。实际上,大学平均绩点在很大程度上能预测出一个学生在研究生院的表现(就像你在下一章节中会看到的,两者的相关性至少能达到0.3),研究生入学考试分数同样重要。这两项标准是相互独立的,因此同时使用这两个标准进行评估比单独使用其中一项要更有效。而加上推荐信之后,对学生评估的准确率就更高了。
然而,半小时的面试结果与一个学生在本科或研究生阶段的表现仅仅存在不到0.1的相关关系,同样的情况也可见于陆军军官、商务人士、医学院学生、和平队志愿者和其他各类面试中。那是一种相当不准确的预测,不会比投硬币预测好太多。其实人们如果只是以面试该有的价值来看待它,那么结果并不会太糟,只要不将它当作决定性因素就好。然而人们总是在过于看重面试的误区中让自己逐渐偏离准确结果。
实际上,人们过度看重面试的价值,以至很容易最终事与愿违。他们认为,面试表现比平均绩点高更有说服力,面试会比基于和候选人长期接触而产生的推荐信更能预测候选人在美国和平队的表现。
对于“面试”,我们应当明白:如果对于一个学校或一份工作的候选人来说,可以在他的申请材料中获取重要的、有价值的信息,那么最好不要再面试他了。如果你能够以面试真正具有的并不那么重要的价值来衡量它,那么它就不可能真的影响你的判断。然而,我们几乎无法抑制自己要过度看重面试的倾向,因为我们对于通过直接观察一个人而了解其能力和品性有着不切实际的自信。
这就像是我们将面试中对某个人的印象看作对他进行了全息摄影的结果——只有一些微小的、模糊的结果是可以确定的,但是那并不是一个人完整的样子。我们应当把面试看作对一个人进行了解的微小的、碎片化的,甚至可能是有所偏差的侧面。想想盲人摸象的故事,你应该不想成为其中的一个盲人吧。
面试错觉和基本归因谬误同出一源,它们都是我们将所获取的不完整的信息夸大的结果。进一步来说,基本归因谬误就是我们高估了一些确定性的性格因素而忽视了环境因素,这会让我们对于面试中获得的信息产生怀疑。更好地理解大数定律有助于我们避免更多的基本归因谬误,并减少面试错觉。
我希望我能说自己对于面试有效性的知识会常常让我质疑自己基于面试而得出的结论。然而,效果真的有限。那种我自以为有价值的知识导致错觉的力量十分强大。我不得不严肃提醒自己不要太看重面试——或者其他通过短时间接触就下结论的情形。这一点在我能从其他途径(他人在长期接触中对某人形成的印象、学术记录或者工作成就)获得更充分信息时尤其重要。
当然,我会很容易就记住你在面试中表现出的非常有限的判断力!
离散与回归
我有一个朋友凯瑟琳,她的工作是为医院进行管理实务的咨询。她十分热爱自己的工作,一部分原因是她可以借工作之便去各地旅行,结识新的朋友。她对美食情有独钟,总会去那些受到高度认可的餐厅体验。然而,她常常抱怨,当她第二次再去那些起初觉得好的餐厅时,却再也品尝不到当日的美味了。你觉得原因是什么呢?
如果你说“可能是厨师极大地改变了烹饪方法”,或者猜测“可能是她的期待太高了,以至实际情况会让她失望”,那么,你就忽略了一些重要的统计学的因素。
以一种统计学的视角来看待这个问题,那么你首先应当想,凯瑟琳在任何一个场合、任何一家餐厅吃到特别美味的食物总存在一种偶然因素。当一个人在不同情形下在同一家餐厅吃饭,或是一群食客于某一个时间在某家特定的餐厅吃饭,人们对于好吃与否的评断标准都会存在差异。凯瑟琳在某家餐厅吃到的第一顿饭可能只是马马虎虎(甚至更糟糕),也可能极其美味。这种变化便是我们评断食物质量的变量。
任何连续的变量(会存在从一个极端到另一个极端的连续完整值域,比如身高),和与它相反的非连续变量(比如性别或是政治倾向)相比,都会有一个均值和一个围绕均值分布的值域。基于这一点,我们就不难理解凯瑟琳总会感到失望:有时她第二次去同一家餐厅的体验会比第一次差,这几乎是必然的(当然有时候第二次的体验会好于第一次)。
但是我们还要进一步分析。我们可以预期,凯瑟琳对一家之前有着不错印象的餐厅的看法会改变,认为它不如从前了。这是因为,越是接近一个给定值的平均值,那么它就越会显得不出众。一个值距离均值越远,则那个值越珍贵。因此,如果她在场合1中吃到了美味的一餐,那下一餐就可能就没有那么美味(在值域上处于极端位置)了。这对于所有符合正态分布定义的变量都是成立的,该曲线被称作“钟形曲线”,如下图所示。
正态分布是一种数学上的抽象表示,但是其形态时常惊人地近似于连续变量的分布——每周由不同母鸡下的鸡蛋数量,每周制造的汽车变速器中出现的差错数量,人们的智商分数分布几乎都近似于正态分布。没有人知道这究竟是为什么,但这的确是事实。
有许多种方式可用于描述在均值周围分布的样本的离散情况。其中一种是值域,即在可见样本范围内用最高值减去最低值。一种更有用的描述离散情况的工具是以均值为基准而产生的平均离差。如果凯瑟琳在不同城市的餐厅品尝的第一顿美餐的平均质量是“非常好”,而均值的平均离差分别为“很高”(高的一边)和“一般好”(低的一边),那么我们会说针对凯瑟琳第一顿美餐的质量均值而产生的平均离差(离散程度)不算非常大。如果平均离差的范围是从“极好”到“极普通”,那么我们认为离散程度很大。

智商得分的正态分布图,均值为100,图中展示了对应的标准差和百分等级
当然,还有相当多的有效测量离散情况的方法,我们可以借此计算任何变量,它们可以被赋予连续的数值。这就是标准差(或者称作SD,可以用希腊字母δ表示)。标准差应当是数据集中的每一个数据与均值的离差平方的算术平均数的平方根。从概念上讲,它不同于平均离差,但是标准差有一些极其有用的属性。
图中的正态曲线被标准差划分成几部分。大约有68%的值分布在距离均值正负一个标准差的值域内。以智商测试分数为例。大多数智商测试是以具体分数为结果的,因此平均值常被设定为100,而标准差为15。若一个人的智商测试得分为115,则他比平均得分高出了一个标准差。均值和比均值高一个标准差的值的差距是相当大的。一个智商测试得分为115的人被认为可以完成大学学业,甚至能完成一些研究生层次的学业。社会中的典型职业分为专业类的、管理类的和技术类的。一个智商测试得分为100的人大多只会完成一些社区大学或大学预科课程的学业,有时只完成高中课程要求就足够了,而他们未来的职业主要是商店经营者、职员或者商人。
另一个有关标准差的有效事实是百分位数值与标准差之间的关系。找到比均值高一个标准差的点,大约有83%的样本值都比该点表示的值要小(在图中对应区域为自“+1δ”点向左)。正巧在比均值高一个标准差的那个点上的值在整个正态分布中的排位为前16%。剩下的16%的样本值高于这84%的值。有几乎98%的样本值落在比均值高两个标准差的点的左侧(即小于“均值+2δ”)。正好落在“均值+2δ”点上的值在整个值域中的排位为前2%,即只有剩下的2%的值大于它。几乎所有的值都会落在距离均值正负三个标准差的区间里。
了解了标准差与百分等级之间的关系可以帮助我们判断生活中遇到的大部分连续变量的情况。例如,标准差常被用作金融领域的一个测量指标。一项投资的收益率的标准差被用于测量投资的波动性。如果一只特定的股票在过去10年中的平均收益率为4%,其标准差为3%,这意味着,你能做出的最接近实际的猜测为:在未来,在68%的时间当中,收益率会是1%~7%;在96%的时间当中,收益率会是–2%~10%。这种情况会很稳定。你不会因此暴富,但也不大可能因为股票暴跌而贫民窟。如果标准差为8%,那么在68%的时间当中收益率会是–4%~12%。你可能会因为这只股票大赚一笔。有16%的时间里你将会拿到12%以上的收益率。另一方面,有16%的时间你的损失也会达到4%以上。这是很容易发生的。有2%的时间你的损失可能会达到12%以上,有2%的时间你的收益又会达到20%以上。你可能会突然间赚大钱,也可能穷得连衬衫也穿不起。
所谓的价值型股票是那些在收益和损失的变动性上都很低的股票。它们可能每年只需你付出2%、3%或4%的股息,既不会在牛市时上涨得太多,也不会在熊市时下跌得过多。所谓的增长型股票则是其收益之间存在很大标准差的股票,即同时具有股价飙升的潜力和股价暴跌的风险。
金融顾问一般会建议年轻的投资者选择增长型股票,并且在熊市和牛市时都坚持不抛售,因为在较长时间段内增长型股票总是能化险为夷,最终增长。而对于年长的投资者,顾问们则建议他们尽量购入价值型股票,这样就避免了在正逢退休之时被熊市套牢。
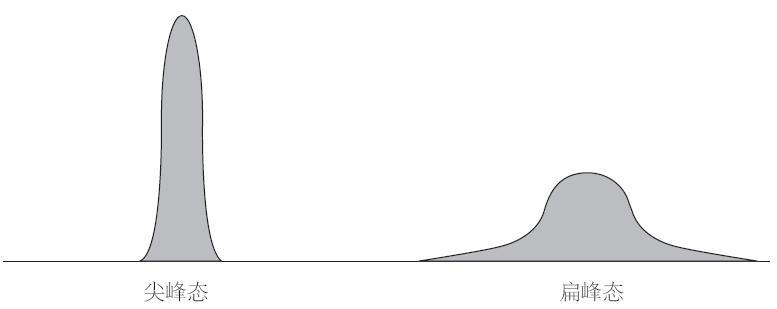
有趣的是,你刚才读到的各类正态分布曲线都有其独特的形状,只有时候会像“钟形曲线”。曲线的峰态(凸出的部分)形状迥异。尖峰态曲线(狭窄型)看上去像20世纪30年代漫画书上的火箭舱体,有着高峰顶和较短的尾部。扁峰态曲线(宽阔的)则像是一条吞下了大象而腹部鼓起的蟒蛇,它有着低峰顶和较长的尾部。然而,无论是哪种形状的曲线,只要是符合正态分布,就会有68%的样本值落在距均值正负一个标准差的区域里。
现在让我们再回到凯瑟琳的问题上,为什么她总会对自己开始评价甚高的餐厅的美食感到失望呢?我们已经明白,她对餐厅中的食物的具体评价是不断变化的:比如从“极其厌恶”(1%的排位)到“极其喜爱”(99%的排位)。假设凯瑟琳吃了一顿饭,认为它在自己的评价体系中的排位达到95%或者更高,即比她吃过的94%的饭都美味。现在,请大家就自己的吃饭经历问自己以下问题:是否认为有很大的可能性,所有你第一次吃到的餐饭都会是特别美味的,或者其中只有一些是特别美味的?如果你认为自己不会期待所有的饭都会特别美味,那么对于第二顿饭的期待值就至少会比极其美味的第一顿饭低一点儿。
有关凯瑟琳的第二顿饭的体验可以被看作样本向均值回归的一个范例。如果人对于饭的感受(喜爱程度)呈正态分布,极端值几乎不存在,因此紧跟着极端值的某一次特定感受会低于极端值。这样,最极端的情况就往低于极端的方向上回归了。
回归效应在日常生活中随处可见。为什么今年的棒球新人总是在来年表现得令人失望?因为,新人在第一年的表现是偏离其真分数的离散值,第二年他别无选择,只会表现得逊色。为什么在第一年增值超越其他股票的股票常在第二年表现得平庸很多,甚至更糟糕?原因还是“回归”。为什么在三年级表现最差的孩子在下一年反而表现得好了一些?依然是“回归”。以上这些例子并不是说事物的走势只有回归这一种。均值的分布并不是一个黑洞,能把所有的极端值都吞没。还有其他一些因素在同时发挥作用,让事物发展得更好或者更糟。虽然我们还不知道形成正态分布的确切原因,但是我们需要明白,极端值之下总是有不那么极端的值跟随着,因为在综合因素的作用下,极端值不会一直维持原状。今年的棒球新人恰好有一位发挥得异常出色的教练来调教他;在今年的一系列比赛中,这位新人遇到的对手都相对较弱;他在今年正好和自己心爱的女孩订婚了;他的身体健康状态堪称完美;他没有受到任何伤病的困扰,等等。而在下一年,他因为肘部受伤而缺席了好几场比赛;那位优秀的教练去了其他球队;他的家人患上了严重的疾病,等等。生活中总是有各种不可预知的事情发生。
下面有两个与回归原则相关的问题(可能会令人惊讶):第一,一个年龄在25~60岁的美国人在某一年成为全美收入最高的1%的人中的一员的概率是多少?第二,一个人连续10年成为全美收入最高的1%的群体中的一员的概率是多少?
你可能无法想象,在美国,一个人成为收入最高的1%的群体中的一员的概率为11%,而一个人连续10年跻身该群体的概率为6‰。这还只是某一年的情况。这些概率数字变化令人震惊,因为我们不会自发地想到,像收入这种事情的变化性会这么高,并且易受到回归效应影响。但是,个人收入在多年中的分布情况也有很大变动性(尤其是收入分布的高点上)。极端收入在人口总体中出现得极少。而正是由于它们极端,所以它们不太可能会反复出现。因此,那些令人讨厌的1%的最高收入群体中的大部分人其实都在走下坡路,这样你可能会善待他们一些!
同样类型的数据也适用于低收入群体。超过50%的美国人在一生中至少会有一次变得贫穷,或者进入类似的状态。相反,并没有那么多人会在贫困中度过一生。一直靠领取救济金度日的人也极少。那些一度需要依赖社会保障生活的群体中的绝大部分人只会在几年中是这种状态。说到这里,你也许要对这些生活困顿的人多一点儿好感了。
我们可能因为不会利用“向均值回归”的框架分析事情而犯下许多严重的错误。心理学家丹尼尔·卡尼曼曾告诉一群以色列飞行教官,如果想改变一个人的行为倾向,那么赞扬比批评有效得多。有一位教官反驳卡尼曼,他说赞扬一个飞行员差劲的演习行动会使他表现得更糟糕,相反,训斥这个表现差劲的飞行员会让他在下次演习中有所提升。然而,这位教官忽略了新手飞行员的发挥是不稳定的,在一次完美的飞行训练之后,他的表现会有“向均值回归”的趋势,或者甚至会有更糟糕的表现。从概率的角度来看,在一次上佳表现之后,下次顶多可以期待他会有接近于平均值的表现;在一次糟糕的表现之后,则可以期待下次会好一些。
如果教官建立了表现是连续变量的概念,即一次极端值之后只可能出现接近极端值的状况,那么他多半只会看到他的学生下一次的表现更糟糕。他必须强化积极方面,以求学生有好于平均水平的表现,让自己成为一个更好的导师。
飞行教官所犯的错误会因为我们都有的一把认知的双刃剑而变得更严重。我们都是卓越的因果关系制造者。如果存在一个结果,我们几乎都能找到解释。
随着时间推进,我们由观察到的不同结果,都能很容易地给出因果解释。然而大多数情况下,其实事情发展并没有我们强加的这种因果——它只是随机发生的。当我们已经习惯于看到一件事发生之后接连会发生另一件事时,这种强加因果的倾向就越发强烈。看到这种关联我们几乎会自发地进行因果解释。如果我们能对这种进行因果解释的行为保持警惕,那么我们将会获益匪浅。但是,这里仍有两个问题:第一,解释来得太容易了,如果我们能意识到自己制造这种因果关联有多么草率,我们就会对它不那么相信了;第二,在大多数情况下,如果我们对随机性的概念有更深的了解的话,因果解释就会显得很不恰当,甚至我们都不会做出这样的解释。
让我们再举几个应用回归原理的例子。
如果一个孩子的母亲的智商是140,其父亲的智商是120,那么你认为这个孩子的智商最有可能是多少?
160 155 150 145 140 135 130 125 120 115 110 105 100
精神治疗师会对许多病人提及“前恭后敬效应”(hello/goodbye effect)。对于病人讲述病情而言,治疗开始前,他们的实际病情没有他们说的那么糟,而治疗结束后,他们的实际病情也没有他们说的那么好,这是为什么?
如果你说这个孩子的智商——父母两人一方智商为140,另一方为120——会达到140或更高,那么你并没有考虑向均值回归的现象。120的智商是高于常人平均水平的,而140也是高过平均值的。除非你认为父母的智商完全决定了孩子的智商,否则你就得预测这个孩子的智商水平会低于父母智商的平均值。因为父母智商平均值和孩子的智商的相关性为0.50(我想你可能不知道这一点),因此孩子的智商值应该为父母智商平均值和全部人口智商平均值的中间值,即115。超级聪明的父母生出的孩子也仅仅是一般聪明而已。不过,超级聪明的孩子的父母的智商也可能只达到一般水平。回归是双向发挥作用的。
对于“前恭后敬效应”的通常解释是,病人为了寻求救治会故意表现出糟糕的状态,而在治疗结束时则想迎合治疗师。无论这种解释的真实性如何,我们都会看到病人在治疗结束时的身体状态要好于治疗开始时,因为他们在治疗过程中的情绪比平时要糟糕,并且仅仅是随时间流逝,他们的状态也会向均值回归。你可能以为“前恭后敬效应”在有些治疗中不会出现,而事实上,所有类型的医生大体上都经历过这样的时候:一个病人的身体状况无论怎样都会随时间推移而改善,除非病灶不断发展。这样看来,任何一种干预治疗都会显得相当有效。“我喝了一些蒲公英汤,我的感冒彻底好了。”“我的妻子刚得流感时就喝了龙舌兰根榨出的汁,所以她感冒的时间比我少了一半。”那种“恰好是他”的统计加上事后颠倒因果的解释之法促生了大量万灵药的制造商。他们信誓旦旦地宣称,相当多的病人在服用他们的药品之后身体状况好转了。
不过,关于回归这一概念,我自己也多少获得了一点新知。上述讨论从大数定律和共变或相关性的概念中得到了一些启示。具体的内容留待下一章继续讲述。
小结
在考虑某件物体或事情时,应当时时将其当作整体中的样本来加以考量。在某一特定情境下在某家特定餐馆吃到的饭的质量,某一个运动员在某场比赛中的表现,我们待在伦敦的那一周的降雨情况,我们在派对上遇到的一个人到底有多好——这些都需要考虑到样本在整体中的状况。而我们在对所有这些变量进行评估时都或多或少犯了错误。在其他条件相同的情况下,样本容量越大,就越可能让一个错误被另一个错误消解,从而让我们更接近总体的真分数。当某些事件很难用一个数字来评断时,就像许多可以很容易通过编码来评断的事件一样,那么此时大数定律就能够发挥效用了。
基本归因谬误主要是由我们忽视情境因素的倾向而导致的,但是我们“忽视掉一个人只是组成人类行为的一个微小样本”这件事也是导致错误的原因。这两个错误引发了访谈错觉——我们总是对自己过度自信,相信从某个人30分钟的言行里就能了解他。
只有当样本不存在偏差的时候,增加样本容量才能有效减少错误。最佳方式是给总体中的每一件物品、每件事或每个人同等的机会被选为样本。至少我们得重视样本偏差出现的概率:在卓希皮亚公司时,我和简相处得轻松愉快,还是说因为她的挑剔我总感到紧张?如果本就有偏见存在的话,更大的样本量会让我们对自己的错误估计更有信心。
标准差是一个便捷的可用于我们衡量连续变量在均值附近离散情况的指标。某个给定类型的样本的标准差越大,我们越无法确定一个特定样本值能否接近样本均值。某一种投资类型若有较大的标准差,则意味着它未来价值变化的不确定性会更大。
如果我们知道某个样本值位于连续变量正态分布曲线中的极端位置,则新出现的样本值将会不那么极端。一个在上次考试中获得最高分的学生可能下次考试也确实发挥得不错,但他不太可能再次拿到最高分。去年某个领域的10只表现最佳的股票在今年不可能蝉联十佳。极端分数或其他一些极端值的出现是因为它们在当时的情境下恰好吉星高照(或霉运当头)。这些幸运符下次可不会在同样的位置出现的。