
“错误的旗杆”
如果是一些基础性的因素,比如网点选址、产品线或者产品,不能够与客户需求相适应,那么就算产品再智能、合作伙伴再优秀,也无济于事。遗憾的是,我们总是会以南辕北辙的标准来衡量这些因素。
网点选址十分重要。在决策过程中,应该遵循一定的逻辑,并听取多方意见,尤其是在贸易领域。然而在现实中,很多选址决策是基于决策者自身的主观逻辑的,并不是基于客观因素。我们也可以这样说,在规划和优化选址的决策过程中,实践情况与逻辑理论偏离甚远。
事实上,用于验证选址是否合理的统计学方法早就存在,并且经过了实践的检验。从本质上看,这种方法并不特别复杂,而且在过去的10年中没有发生太多根本性变化。在做出选址决策前,一般来说,我们要分析购买潜力、核心目标客户的行动路线以及步道的使用频率等。这样分析的结果往往是,我们会让一个新规划的建筑市场直接毗邻其区域内最强劲的竞争对手,比如选址在一个拥有相似产品线的家具市场的正对面,未来可能还会为这些同一竞争领域的商家配套加油站等设施。
针对区位选择的聚类分析造成了德国批发零售行业扎堆的现象,具有直接竞争关系的企业挨得很近,并且贸易模式也很相似。一位选址战略家认为,导致这种“扎堆”现象的原因是“旗杆效应”。有时候,树立这根旗杆意义非凡,它可以是一种优越性的象征。在贸易领域,我们提到“旗杆效应”时,往往会引发数据使用中的理解误区。当一个看起来非常具有吸引力的选址进入我们的视野时,我们总是会产生一种念头,我们一定要把新址定在这里。这样做是有原因的,因为这个地点享有很高的关注度,并且与其他地方互通方便,因此具有战略性价值。这些选址之所以能够获得我们的关注,也常常是因为重要的竞争对手已经在此处建立了一个网点,且这个网点多年来经营得很成功。
但是,绝大部分批发企业在网点发展过程中并没有孕育出一种战略去指导不同地区、不同经营模式的网点,凭借它们的产品去匹配客户多元化的需求。一般情况下,我们会尝试去建立一个新网点,然后利用在其他地区业已成熟的经营模式,去满足客户既存的(有宏观市场调研数据支撑的)需求。不同地点的网点间差异巨大,显见的包括网点大小、场地结构以及产品线等因素,大部分并未被考虑在内。在本书的第二部分,在谈到客户旅程的时候,我们已经提及这一点了。网点负责人的任务就是,利用成功的经营模式,去满足具有区域特色的客户需求。但是令人着急的是,只有要在做出选址和经营模式选择的决策时,企业才会想要去分析具有区域差别化的客户需求对选址策略的影响。这绝对是一个决定性错误。大型的贸易连锁企业必须马上着手研究针对不同市场的经营策略。智能数据冠军企业也应该从客户角度出发,持续地考虑选址决策的问题。理想的情况应该是这样的:
☆第一步:首先要了解市场,把客户进行分类并排出优先级,然后针对不同类别的客户提出差异化的经营策略。在此过程中,需要注意客户旅程情况,并且明确定义出网点经营模式的角色作用。
☆第二步:确定我们在网点选址过程中需要怎样权衡哪些标准。
☆第三步:开放性地研究客户的购买潜力。借助于捷孚凯(GfK)和尼尔森市场研究公司数据库中的邮政编码信息来研究,会相对容易一些。
☆第四步:将差异化的客户购买潜力情况与自身选址、最重要竞争者的选址情况进行比较,发现市场空白点。
☆第五步:系统化地评估潜力区域内的客户需求,评估有市场研究数据支撑的网点,评估既存的、有相似客户潜力的网点的交易数据。
☆第六步:到这步,我们才开始去寻找具体的选址。虽然存在例外情况,但在一般情况下,我们要避免与强劲竞争者挨得太近。如果物理距离太近,那么就要经受考验,与已经“树起旗杆”的竞争者相比,我们是不是能够以一种全新的贸易模式去更好地满足客户需求。
☆第七步:利用可掌握的全部数据源,详细地分析网点的微观环境,比如,利用谷歌地图系统性地检测购物高峰期的交通情况。基于证据的决策是主观态度的前提。
☆第八步:参考差异化的选择标准,确定正确的选址和经营模式。
如果此时有人觉得这样做很乏味,宁愿借助智能手机数据去做大数据客流研究,我们觉得这也是可以的,但前提是掌握了相应的技术手段。其他人最好还是优先考虑一下上述智能数据解决方案。
美国沃尔格林公司借助Excel实现选址优化
每一个网点都具有区域特性,尤其是药品销售网点。拥有近7000个销售网点的美国药品销售连锁企业沃尔格林公司,在多年前采用了一种独特的方式,对客户的购买数据与住址信息进行了比对研究。结果发现,最大购买距离是两英里!住址距离一个网点超过两英里的客户就基本不会去这个网点买药了。基于这种数据研究结果,沃尔格林公司的企业战略人员可以发现前文提到过的网点发展过程中的市场空白点,也可以发现网点量供过于求的情况。另一方面,研究结论更容易转化为实践,即企业负责人可以更好地去优化在每个网点投入的广告宣传预算。
沃尔格林公司主要通过在报纸上安插宣传折页进行广告宣传,这些广告折页会随报纸被分发到全国所有有邮政编码覆盖的区域。研究人员利用Excel汇总数据信息,识别出哪些邮政编码覆盖区域与最近的药品销售网点间的距离大于两英里。随后,这些区域的广告宣传预算将被取消。沃尔格林公司通过这种方法,累计节省了500万美元的费用支出,但销售额却丝毫没有受到影响。
在正确的地点采用正确的销售模式
在下一章我们会看到,数据是如何使多渠道贸易成为可能并促进其发展的。在此处我们先重点强调,在不同的销售模式下,在与客户直接接触的过程中满足客户需求的能力,是在大多数行业和商业领域建立多渠道战略的前提。迄今为止,尤其是在贸易领域,这一点被强烈地忽视了,因此这反而为我们提供了机遇,使我们有可能在激烈的市场变革中占据竞争优势。在贸易领域,大型的连锁企业可以通过上面八个步骤很清晰地识别出哪些选址对全产品线网点来说是合适的,哪些客户需要购买受监管类药物,哪些位置适合设立快闪店,以及哪些地区的居民喜欢在下班的路上顺便开车去便利店买东西。获得这些认知不仅仅对建立新网点有帮助,对优化现存网点网络也有益处。
在不同的销售模式下,在与客户直接接触的过程中满足客户需求的能力,是在大多数行业和商业领域建立多渠道战略的前提。
当然,这也不仅仅适用于分销贸易,对B2B贸易也起作用。在B2B领域,有时更容易发掘这些认知的应用潜力,就比如我们在前文提到的一个智能数据项目中,优化一个中型家装服务供应商的外勤资源那个案例一样。
“二战”之后,在德国经济奇迹那些年,德国企业经历了持续性的高速增长,几乎没有经历经济萧条的阶段。在这期间,这些企业的分支机构网络也得到了生机勃勃的发展,但那时的发展主要是凭“直觉”。
借助邮政编码和交易数据信息,在分析客户需求的时候考虑到区域差别化的因素,这种方式与之前的市场渗透截然不同。在一些地区,外勤人数过多,但产生的经济效益少。而在另一些区域,外勤人数又与客户需求潜力不符,不能满足市场竞争的需要。在数据的支撑下分析外勤人员到客户处去的实际路程时间,我们会发现,其实是外勤营销区域的划分有问题。在直线距离规划和路程规划的辅助下,我们可以优化外勤人员的路程选择。通过重新划分外勤营销区域,外勤人员整体的工作饱和度在原基础上可提高20%,人均工作饱和度范围从之前的60%~120%调整为基本每个外勤人员都可达到95%。
如果我们把数据在图表中进行可视化叠加,我们可以直观地总结出很多有意义的功能整合措施。加上一点儿对路程数据的统计学分析,我们很快就可以得到新的区域划分方案,并重新进行资源配置。不需要关闭任何一个网点,也不用裁减雇员。此外,这也是一个长期的转型方案,企业可以在后续逐步实践。
无论是设计建设新的网点,还是从根本上重新规划既存网点,都是一项长期的工作,远比在纸面上基于数据提出的优化方案要复杂。如果亲身参与到这项工作中就会发现,在实施过程中存在很多的限制和困难,比如投资额巨大、可支配用地面积有限、审批障碍重重、施工制度限制、长期租赁合同事宜、劳务法律制度要求、不同网点间员工的抵制情绪等。数据只能够辅助我们做出关于网点发展的正确决策,并协助我们通过实验项目获得关于网点具体设计应用于实践的认知。在跨越实践中的种种障碍上,数据能做的十分有限。但是,在优化产品线方面,数据能发挥的作用就很大了。在促进供求关系协调并符合区域性特征方面,数据是必不可少的,在某些情况下,我们甚至需要实时数据来监控供求关系平衡问题。

实时优化产品线
当美国气象台预测佛罗里达州将有飓风时,不仅仅是当地的救灾组织做好了应急准备,当地的沃尔玛超市也备足了食品,以应对客户购买需求的变化。超市会立即向恐受灾地区派出货运卡车,这些卡车负责向灾区输送物资商品,如桶装水、压缩液化气筒、煤油灯、保质期较长的牛奶制品、烤面包干等。还有一种家乐氏公司的名叫Poptarts的华夫饼,甜甜的,质地有些黏稠,很多在婴儿潮年代出生的人小时候经常吃这种华夫饼,它会让人回忆起儿时和谐安宁的生活,因此在面临危险的环境下,人们似乎特别爱买这种华夫饼。
沃尔玛在掌握贸易客户数据信息方面几乎可以与亚马逊比肩,算是世界上数一数二的公司,同时,沃尔玛也是世界上为数不多的真正实践大数据应用的公司之一,在数据应用领域已经取得了极大的竞争优势。一场飓风的来临,只能算是持续优化产品线过程中的一个显性极端事件。沃尔玛公司能够做到实时监测某一地区多变的天气数据,并能够将监测结果与产品销售数据关联分析,随后会将分析结果应用于产品供应及定价决策中。凭借此种做法,一方面,沃尔玛公司具备了极其灵活的物流配送能力,成为20年来最具市场分析能力的市场竞争者之一;另一方面,沃尔玛公司的仓储成本显著降低。
现阶段,几乎在所有的大型欧洲贸易企业的贸易研究项目中,都能发现一个基本的诉求,那就是尽快掌握像美国贸易企业那样的数字化竞争实力,并用尽可能短的时间,优化自身的产品线,以满足变化了的市场需求。树立这样的项目目标是有原因的:
智能地优化产品线,能够使我们在数据的辅助下,更好地对标客户需求,提高客户价值,与此同时,还可以优化库存、降低成本、提高市场营销有效性。
然而,一件事情的结果,往往不如人们预想的那么好,在这件事情上也是这样。如果我们想系统性地优化产品线,成功与否在很大程度上取决于销售和市场研究数据。试点市场和实验室数据显示,由于市场竞争情况的不同,实际的优化结果差异较大。在产品线确实存在优化空间的前提下,地区性的结果差异往往跟市场或企业领导者的经验和市场直觉有关。如果一家贸易企业能够将沃尔玛公司视为自身数字化竞争力的榜样,那自然是好的。但不是每一家企业都能够做到像沃尔玛公司那样,通过系统性地分析交易数据和市场潜力数据,及时(最少按周)调整区域产品种类,(最少每日)调整产品定价,使供求相匹配,同时还能够重点关注某一产品门类的情况。
智能数据冠军企业通过以下5个步骤,获得优化产品线的能力:
1.系统性分析购物车信息;
2.获得灵活调整产品供给和产品定价的能力,并且能够衡量调整结果;
3.关联产品门类数据,以便于进一步优化产品线;
4.缩短使产品供给与产品定价相互匹配的时间(从按周到逐日,再到实时调整);
5.基于上述4个步骤的经验,构建一套基于数据的,对其他市场、工厂、企业等领域具有推广性的优化流程。
如果连锁商店能够坚持品牌定位管理,那么对商品门类和产品种类的细分将取得成效。
产品种类、产品定价细化的作用是有限的,这并不难理解。因此,尤其是连锁商店,还应该关注网点品牌定位的问题。如果一家位于柏林或慕尼黑的网点,在箱包区出售日默瓦行李箱,但是哈根和吉森市内的网点,却在售卖不知名品牌的行李箱,那么对消费者而言,这家连锁商店的品牌定位将日渐模糊。
采用不同的形式去强化产品细分,这对大多数贸易企业来说都有好处,我们在这一点上是有共识的。如果连锁商店能够坚持品牌定位管理,那么对商品门类和产品种类的细分将取得成效。再以一家大型食品商店为例,这家商店对它的客户群体以及客户需求进行了持续性的细化分析,然后这家商店将可实现根据不同网点主要客户群体类型,将每家分支网点进行功能定位,将网点分为日常网点、中等网点和高档网点三类。然而,这只是第一步。
根据不同的行业,采取不同的细化形式,这是十分有必要的,因为不同行业的网点,其功能可能是截然不同的。银行网点就是一个很好的例子,汽车行网点也是。以前,人们在买某一辆车之前,平均要去车行逛4次,而现在,车主基本上去一次车行,就能决定是否购买。通过产品配置软件、网络浏览和汽车行的官网查询产品信息,这个过程在“客户旅程”中占比越来越大。显而易见,从客户的角度出发,汽车行的功能定位发生了根本性变化。其实,早在一二十年前,汽车生产商就意识到了物理网点功能定位的问题。当时,几乎所有的生产商都在考虑多销售渠道战略并赋予物理网点新的功能定位。但是当时,我们对“到底哪种物理网点定位才是符合未来发展趋势”的认识还很少。从汽车生产商和销售商的角度,谋求物理汽车行网点的替代性转型,仍然需要尝试和探索。
所有智能数据解决方案都需要遵循的一个根本原则是,要处理好投入与产出的关系,这也同样适用于上文提到的方法和措施。在实际工作中,要想处理好投入与产出的关系,能够衡量和量化产出是大前提。此时,基于数据的产品线优化就显得十分必要了,因为只有基于产品优化细分,我们才能够为解决方案的每个阶段设计合适的对照组试验,进而才能够从根本上推动转型。
DDI,这三个字母在全世界数字化复兴时期获得了广泛关注。DDI是Data Driven Innovation的缩写,即数据驱动创新。在理解或者介绍数据驱动创新这个概念时,人们往往会提到其带来的破坏性影响。我们承认数据的破坏性影响力,并且在《我们的数据》一书中详细描述了数字能够产生破坏性影响力的原因。与此同时,我们也相信,改变人们对数据影响力的看法只是时间的问题,人们会意识到,在某些领域使用某些数据,将会给世界带来改观,将对企业及其市场、销售部门产生积极影响。只是现在,人们还热衷于关注数据驱动创新带来的破坏性的威胁,而不是进步。
数据驱动创新可分为三个层面:
1.数字化技术创造全新的产品和服务;
2.在数据的支撑下,将会孕育出前所未有的商业模式;
3.在数据的辅助下,通过反复的对照组试验,逐步优化既存的产品、服务和流程。
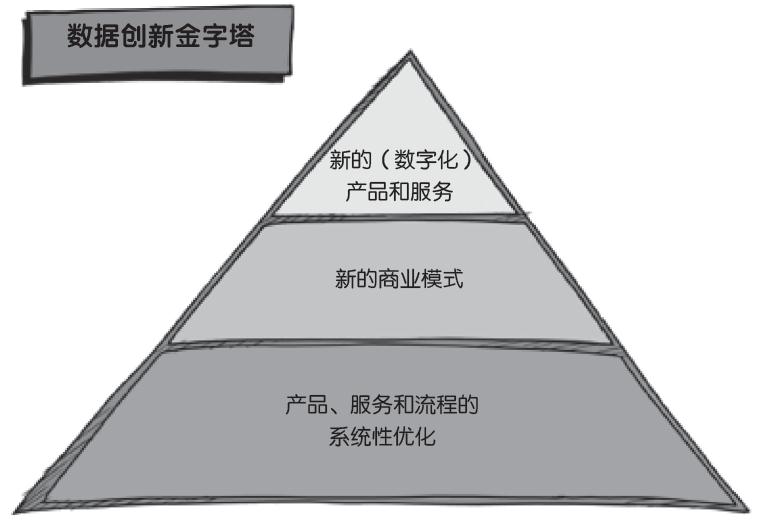
在与企业家交流的过程中我们发现,大多数企业决策者都对前两个层面极其感兴趣,而对第三个层面关注太少。一家德国汽车生产企业不断地思考,如何能够生产出无人驾驶汽车,这自然是有意义的。同样,保险公司的产品研发部门去考虑,在汽车司机可以通过地理数据服务器将他们驾驶车辆的信息和行车信息实时地发送给保险公司的情况下(即使现在还做不到这样),是否可以研发出一个新的个人保险险种,这也是有必要的。
然而,智能数据冠军企业往往会从第三个层面着手,并且在流程长效优化方面倾注最多的资源。例如下列四项智能产品创新案例:
☆一家大型的运动鞋生产企业引导其客户使用个人跑步App。通过研究App使用数据以及特定款式鞋类的销售数据发现,购买某一款顶级跑鞋的消费者,在使用跑鞋方面存在极大差异。基于此种认识,这家企业改变了这款跑鞋的产品定位,将购买这款跑鞋定义为健康生活方式的象征,并且针对特定的消费群体展开了相应的广告宣传。通过这种方式,这家企业促使特定消费群体的生活方式更加健康,另外,通过改变产品定位和市场宣传这两种手段,企业的营业额获得了大幅提升。
☆有一家德国大型家用电器生产企业,对自身产品在东欧地区的销售表现不满意。于是,这家企业尽可能搜集了自己和竞争对手产品的市场、价格以及产品特征等数据。这些数据一部分来自数据库,另一部分由一家专业的产品标准管理组织提供。通过数据分析发现,在对产品购买决策影响较大的产品特征方面,东欧和西欧地区是截然不同的,差异之大远超这家德国生产商的想象。在认识和把握这种差异性方面,亚洲的竞争者似乎表现得更好,或是有更好的数据信息支撑。比如,一个蓝色的、黄油块儿大小的LED(发光二极管)灯泡,俄罗斯的消费者就会愿意多付出50欧元去购买。一个小小的产品特征改良,可能就足以提高产品在客户心中的价值表现。
☆对一家电信供应商来说,消费者最关心的产品特征就是,手机信号的接收质量是否良好。可惜的是,建造和运营通信网络的成本,偏偏是这个行业最大的成本支出科目。一家阿拉伯地区的通信网络供应商在早年便面临市场挑战,网络传输能力的建设跟不上快速增长的市场需求。这个问题使这家通信网络供应商面临客户因不满意通信质量而加速流失的风险。因此当时,这家通信网络供应商的决策层在建设和运营网络方面追加了数十亿美元的投资。如果这个案例发生在一个智能数据项目中,我们会建议这家企业的决策层首先去差别化地关注一下区域客户潜力,然后参考每个通信基站覆盖区域内的客户价值贡献,以及服务满意度尚高的客户群体的追加销售潜力,再来规划网络扩建的进度。这样做的话,只需要利用海杜普(Hadoop)软件就可以提取分析交互数据,成本支出可能也就5位数。相比数十亿美元的追加投资来说,岂止是合算可以形容的。
☆“Emmas Enkel”是小型便利店的迭代产物,即那种新式的、很小规模的、根植于当地消费需求的零售店铺。这些店铺要从8万多件商品中挑选出几千件适合于地区销售的商品,仅依靠直觉恐怕是不行了。现在,它们持续性地关注并利用销售数据,从而做到使所售商品与服务的小区域内不断变化的市场需求相匹配。