
在第5章,我们讨论了比特币挖矿的能量消耗(有些人会说是浪费)是个潜在问题,经济学家称之为负外部性。我们估计比特币挖矿要消耗几十万千瓦的电能。所以一个明显的问题是,这些用来解谜运算的工作量是否对社会有所贡献?这其实是一个资源再生循环的问题,也会增加社会对加密数字货币的政策支持。当然,这个解谜算法也必须满足几个基本的要求,才能够在一个共识协议里被使用。
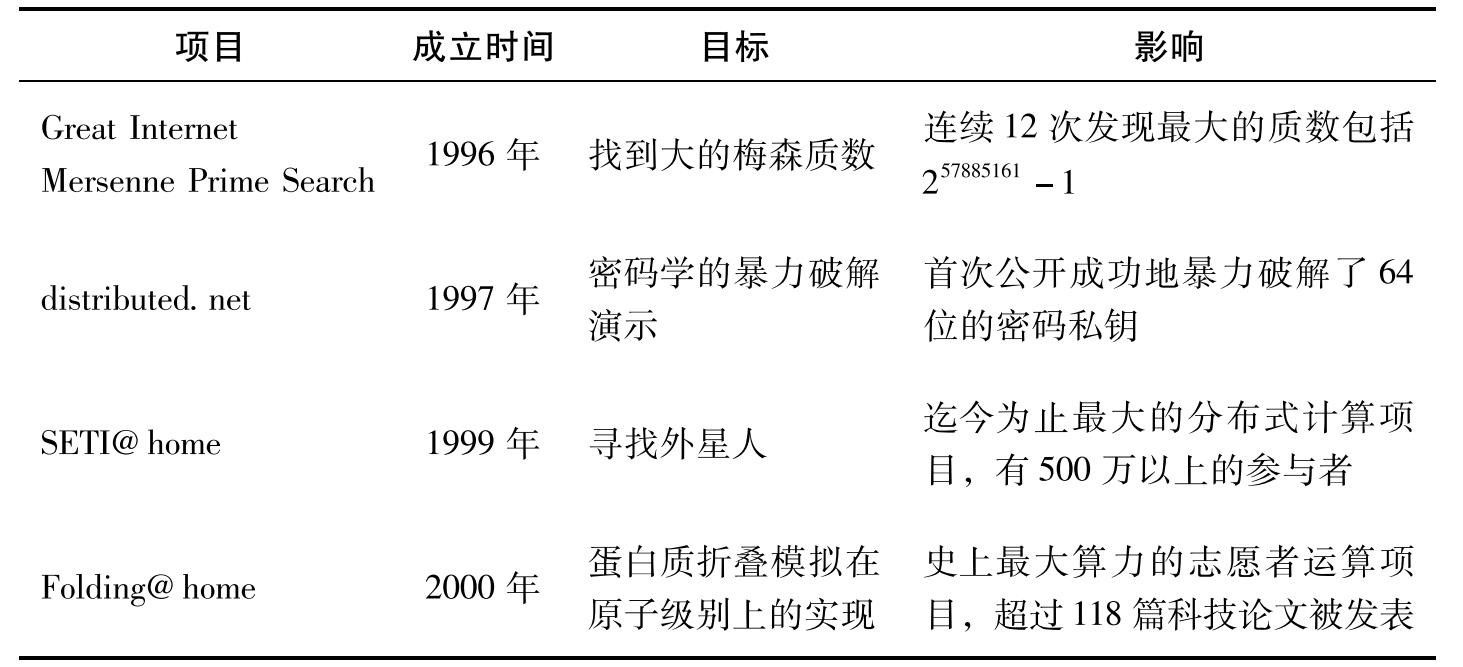
以前的分布式计算项目
在比特币诞生好多年之前,就有利用空闲的电脑[或者叫“空闲周期”(spare cycle)]来做一些其他工作的想法。表8.1列出了最受欢迎的几个志愿者运算项目。所有这些项目都有一个特性,使得它们适合成为解谜算法的运算。具体来说,它们需要解决的都是一种“大海捞针”型的问题,可能的答案存在于一个非常大的空间(或者说范围),搜索空间的每一小部分都可以进行并行的快速验证。最有名的例子是在SETI@home网站上,志愿者们被分配一小段无线电信号,用闲置的个人电脑来分析这段信号可能存在的模式以寻找外星文明,同时分布式计算网站(distributed.net)的志愿者被分配一小段可能的私钥来进行验证。[1]
志愿者运算项目,成功地把一个很大的计算任务拆分成小份的任务,然后分配给每一个志愿者进行运算检查。事实上,这种模式在一个特别的叫作伯克利开放式网络计算平台(Berkeley Open Infrastructure for Network Computing,简称BOINC)上是很普遍的,这个平台被开发出来就是用来给不同的个体分发小份额计算工作的。
在这些应用里,志愿者们主要都是被解决某个问题的兴趣所吸引,即使这些项目通常也会设立一个排行榜来让人们炫耀他们所贡献的算力。排行榜也导致一些人在自己的工作量上作弊,有一些被报告的工作量其实并没有实际完成,这也使得有些项目再分配一些额外的工作去检查网络上的这种作弊行为。金钱,是加密数字货币分布式计算应用的动力,只要技术上是可能的,一定会有参与者尝试去作弊。
表8.1 热门的志愿者运算项目
有效工作量证明的挑战
有了这些成功的项目,我们可以尝试简单直接地利用这些解决问题的成功方法。例如,在SETI@home的项目中,志愿者们被分配一小段无线电信号监听去寻找外星人,我们可以判断,外星人存在的概率,要比解谜算法找到“获胜”答案并且允许找到答案的矿工去创建一个区块的概率小很多。
但这个想法有几个问题。首先,并不是所找到的答案都有同样的概率成为“获胜”的答案。参与者可能会意识到有特定区域会有更高概率找到异类,那么参与者就会有倾向性,只针对一些能产生不同寻常结果的区域进行分析。对于一个中心化的项目来说,参与者被分配工作,所以所有的区域最终都会被分析(当然对最有希望的区域会予以优先考量)。对于挖矿来说,任何矿工可以随意尝试任何区块,所以矿工会先涌向最有希望的区块。如果更快的矿工知道他们可以先尝试最有希望的区块,这就意味着解谜算法可能不是一个过程无关的算法。比特币的解谜算法与之相比就有不同,比特币的解谜算法中用来产生一个有效区块的临时随机数都是完全平等的,所以所有矿工都会随意选择一个临时随机数去尝试。这个问题展示了我们之前都已经习以为常的比特币解谜算法的一个主要特征:一个机会均等的解谜区域。加 入 会 员 微 信
其次,考虑到SETI@home项目中存在着固定的数据量需要被分析的问题,这些数据基于射电望远镜(radio telescope)的观察。随着挖矿算力的不断增长,有可能某一天就没有需要加工的数据了。比特币在这方面也有不同,比特币算法有无限的SHA-256解谜可以被创造出来,这就说明了另一个重要的特征需求:永不枯涸的解谜库。
最后,考虑到SETI@home的项目中,有一个受信任的中心化的管理员机构,负责发现新的无线电信号并判断志愿者们应该研究的内容。同样,由于我们使用解谜算法来构建一个共识机制算法,不可能假设一个中心化的机构来管理所有的解谜,这样我们就需要所有解谜的最后一个特征:通过算法自动生成。
哪种志愿者运算项目可能适合解谜算法
回到表8.1,我们可以清楚地看到,像SETI@home和Folding@home这样的项目不太适合去中心化的共识机制协议,两者都被证明了缺乏我们所列出的上述三个特性。distributed.net上的暴力破解密码学项目可能适用,虽然它们通常被某些公司用来做某种加密算法的安全评估,但是不能通过算法自动生成。我们可以通过算法自动生成被暴力破解的加密方法,但是某种程度上这就是SHA-256不完全原像(partial preimage)算法已经做过的事,并且它没有任何有益的功能。
那就只剩下互联网梅森质数大搜索(Great Internet Mersenne Prime Search,简称GIMPS)项目了,这个最具备可用性。这个办法的挑战是通过算法自动生成(找到下一个比当前最大质数更大的质数),以及谜底空间是不可穷尽的。事实上,质数的寻找确实是无穷的,因为质数的个数已经被证明是无限个的(特别是梅森质数是无限量的)。
梅森质数方法的唯一缺点,是需要花费很长的时间来寻找梅森质数,并且梅森质数非常罕见,事实上在过去18年里,梅森质数大搜索项目一共才发现了14个梅森质数,显然在区块链上每年才增加不足一个区块是不可行的。这个问题看起来是缺乏可调节的难度特性,我们在8.1节讨论过这个特性是非常关键的。无论如何,类似于寻找质数这样的解谜算法,看起来是可行的。
质数币
到2015年为止,唯一在实际中被应用的被证明具有有效工作的系统是质数币(Primecoin)。质数币的主要挑战是为质数找到一个“坎宁安链”(Cunningham chain)。坎宁安链是指k个质数的序列P1,P2,…,Pk,以使得Pk=2Pi-1+1。也就是说,你选一个质数,然后把这个质数乘以2再加1以得到下一个质数,直到你得到一个和数(非质数)。含有2,,5,11,23,47就是一个长度为5的坎宁安链,按照这个规则所获得的第六个数字95并不是质数(95=5×19)。最长的已知的坎宁安链的长度是19(从79,910,197,721,667,870,187,016,101开始),有一个被推测以及被广泛认可但没有被证明过的理论认为,存在一条任意的长度为k的坎宁安链。
现在,要把这个理论变成一个可计算的解谜算法,我们需要三个关键的参数m、n和k,稍后我们会具体解释。对于给定的一个解谜挑战x(上一个区块的哈希函数值),我们选择x上的前m位数。我们可以认为任何长度为k的链或者大于k的答案是正确的,这条链上的第一个质数是一个n位质数并且和x一样有m位的首段数据(n≥m)。值得注意的是,我们可以调整n和k的值,来让这个解谜变得更加困难。增加k的值(需要的链的长度)使得问题难度指数型增长,而增加n的值(链上的第一个质数的长度)使得问题难度线性增长,这就可以让我们对问题难度进行微调。其中,m的值只需要足够大,使得在知道前一个区块的值之前的预先计算方法变得没有意义。
其他我们所讨论的属性看起来已经都有了:结果可以很快被校验,问题本身是无关过程的,题库可以无限大(假设对质数分布的知名数学推导是正确的),然后解谜可以通过算法做到自动生成。实际上,这个解谜算法已经被质数币用了两年,并且对许多给定的k值产生了坎宁安链里最大的质数。质数币还做了进一步的扩展,在其工作量证明中涵盖了其他类似的质数链,包括“第二”坎宁安链,其中Pi=2Pi-1。
这验证了在某些限定的情况下,有效工作量证明是具有实际运用的。当然,寻找大的坎宁安链有用与否,是有争议的。坎宁安链当然也代表了我们已知数学知识宝库的一小部分,其在未来可能会有一些应用场景,但在目前还没有实际的应用出现。
永久币和存储量证明
另外一种有效工作量证明叫存储量证明(proof of storage),也被称为可恢复性证明(proof of retrievabitlity)。不同于需要一个单独计算的解谜算法,我们可以设计一个需要存储大量数据被运算的解谜算法,如果这个数据是有用的,那么矿工在挖矿硬件设备上的投资就可以被用于大范围分布式存储和归档系统。
让我们看一下永久币(Permacoin),这是第一个用于共识机制的存储量证明方案。首先我们讨论一个大文件F,我们假设所有人都认可F的价值并且这个文件不会被改变。例如,当一个加密数字货币上线时,由一个可信任的分发者选择F,这有点类似于任何一个加密数字货币启动时都需要一个创世区块,理想状况下这个文件会具备公共价值。例如,大型强子碰撞(Large Hadron Collider,简称LHC)的实验数据,这个数据已经达到了几百拍字节(petabytes,用PB表示)的大小,对这些数据的备份是很有价值的。
当然,因为F存储量非常巨大,大多数参与者都无法对整个文件进行存储,但我们已经知道,在不需要了解整个文件的情况下,如何使用密码学里的哈希函数来确保每个人都对F认可。最简单的方法是,每个人都认可H(F), 但更好的方法是用一个大型梅克尔树来代表F,所有的参与者都认可梅克尔树的根值。现在,每个人都认可F的价值,证明F的任意一部分是正确的就变得很有效率。
在永久币系统中,每一个矿工M存储着任意F文件的子集FM F。为了实现这一点,当矿工产生一个公钥KM来接受资金时候,他们就对该公钥进行哈希运算以生成一个区块FM的虚拟随机数集,他们必须存储这个数集以实现挖矿的目的。这个子集就会变成某个固定数量的区块k1的一部分,我们必须在这里做一个假设,当矿工开始挖矿的时候,他们有办法获得这些区块——可能是从一个标准文件源地址下载下来(见图8.2)。
F。为了实现这一点,当矿工产生一个公钥KM来接受资金时候,他们就对该公钥进行哈希运算以生成一个区块FM的虚拟随机数集,他们必须存储这个数集以实现挖矿的目的。这个子集就会变成某个固定数量的区块k1的一部分,我们必须在这里做一个假设,当矿工开始挖矿的时候,他们有办法获得这些区块——可能是从一个标准文件源地址下载下来(见图8.2)。
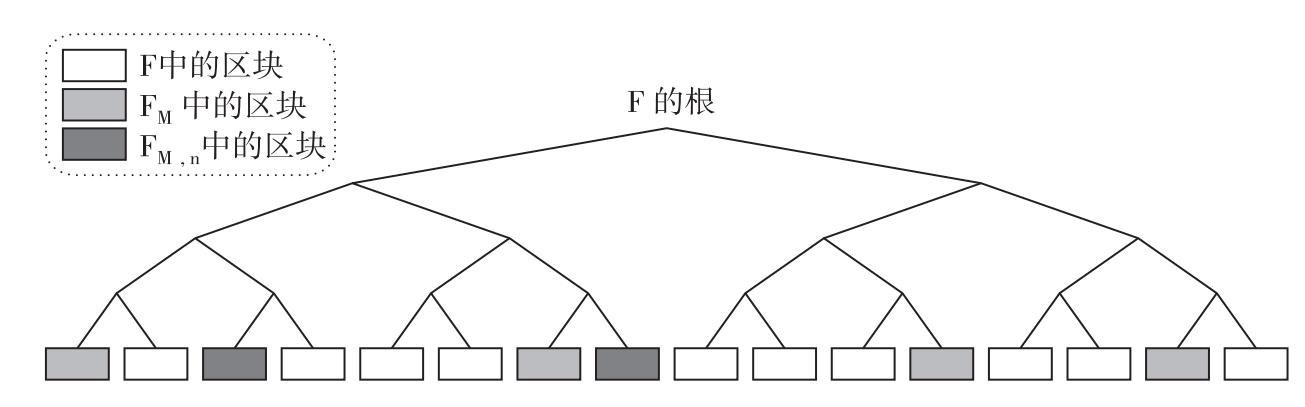
图8.2 在永久币系统中选择一个文件的随机区块
注:在这个案例中,k1=6,k2=2。在实际应用中,这些参数会大很多。
一旦矿工在本地存储了FM,这个解谜算法就非常类似于传统的SHA-256挖矿了。给定前一个区块的哈希值x时,旷工选择一个临时随机数n,将其进行哈希运算并产生一个虚拟随机数子集FM,nFM,这个子集包含了k2<k1个区块。值得注意的是,这个子集是由所选的临时随机数和矿工的公钥共同产生的。最后,矿工对n以及Fk中的区块,进行SHA-256的哈希函数运算,如果计算的结果是低于目标难度的,那么也就意味着他们找到了一个有效的方案。
校验一个解谜算法的结果需要以下几个步骤:
● 校验FM,n是由矿工的公钥KM和临时随机数n共同产生的。
● 通过检验其在梅克尔树节点到全局统一的树根路径,来检验FM,n中的每一个区块是正确的。
● 校验H(FM,n‖n)的值比目标难度要小。
我们很容易看出,为什么解谜过程需要矿工在本地存储所有的FM,n。对于每一个临时随机数,矿工都需要计算FM,n中随机子集的哈希值,如果通过远程访问一个存储空间来获取文件,就会非常慢,几乎不可能实行。
不同于Scrypt算法的案例,如果k2足够大,并没有一种可行的类似于时间内存的权衡方案。如果矿工仅仅在本地存储了一半的FM,并且k2=20,那么在他们找到一个不需要从网络中取回任何文件区块的临时随机数之前,他们必须要尝试100万次,降低一定量的存储负担会以计算量指数型增长为代价。当然,由于k2梅克尔树路径要在所有的路径中被传输和校验,如果k2设得太大,也会使运算变得非常低效。
k1的设定也可以有所权衡。更小的k1意味着矿工需要更少的本地存储空间,因此这种挖矿就更加民主化(更多的人可以参与)。然而,这也意味着,大量的矿工即使有能力提供更大的存储空间,他们也没有动力去存储多于k1个F区块。
同样,这是一个对完整的永久币做了细微简化的方案,但是对我们理解整个设计的关键部分来说是足够的了。最大的应用挑战,当然是找到一个合适的大文件,这个文件要有一定的重要意义,同时也是公共的,需要保存多个备份。如果F文件本身随着时间的推移会发生变化,或者随着时间的变化而调整难度,这样会使方案变得更加复杂。
长期的挑战和经济意义
总结一下本节内容,有效工作量证明是一个非常自然的目标。考虑到一个好的共识机制所需要的其他解谜算法,实行起来也有相当大的挑战。即使如此,至少本文所举的两个案例——质数币和永久币——在技术上是可行的,虽然它们也都有一些技术方面的缺陷(主要都是需要更长的时间去验证解谜结果)。此外,对比在比特币挖矿中动辄数百万美元的投入以及大量电力的消耗,这两种加密数字货币的应用都对社会公益有一些贡献。
有效工作量证明是否应该是纯公益的,有一个有趣的经济学方面的争议。在经济学中,公益的意思是非排他性的,也就是说所有人都可以参与使用,并且是非竞争性的,对公益的其他用途不应该影响其本身的价值。一个经典的例子就是灯塔。
我们这里所讨论的案例,比如蛋白质折叠(protein folding)[2],就不是一个纯公益的项目,因为有一些公司(比如大的制药公司)可以从中获利。实质上,这些机构挖矿的成本会相对变低,因为它们可以获取其他人无法获得的额外利益。
[1] 大约有500万人参加这个计划,包括译者本人。——译者注
[2] 蛋白质折叠问题被列为“21世纪的生物物理学”的重要课题,它是分子生物学中心法则尚未解决的一个重大生物学问题。——译者注